Turbolinks vs the Virtual DOM
On Friday, Nate Berkopec tweeted out:
Side effect of the Turbolinks-enabled mobile app approach - guaranteed to be fast on old/low-spec devices b/c the Javascript is so simple. — @nateberkopec
Think about the operational complexity of React versus Turbolinks. An entire virtual DOM versus "$('body').innerHTML(someAjaxResponse)". — @nateberkopec
He justified his hypothesis by showing that the Ember TodoMVC takes 4x as long to update as a Turbolinks version, which I found odd because his original claim was about virtual DOMs, but the Ember TodoMVC uses an old version of Ember that doesn't use a virtual DOM — Ember's virtual DOM, called Glimmer, didn't appear until 2.0. It injects HTML, exactly what Turbolinks does. The only difference is that that HTML is generated by the browser. It trades a round trip to the server for CPU usage on the client.
Having spent the last year or so studying the performance advantages and disadvantages of virtual-DOM implementations and trying to ensure that Clearwater is fast enough for any app you want to write (including outperforming React), I had a sneaking suspicion that Turbolinks would not be faster than a virtual DOM that uses intelligent caching. I base that on the way HTML rendering in a browser works. This is kinda how node.innerHTML = html works in JS:
- Parse HTML, find tags, text nodes, etc.
- Generate DOM nodes for each of those tags and wire them together into the same structure represented in the HTML
- Remove the existing nodes from the rendered DOM tree
- Replace the removed nodes with the newly generated nodes
- Match CSS rules to each DOM node to determine styles
- Determine layout based on those styles
- Paint to the screen
With a virtual DOM, there is no HTML parsing at all. This is why you never have to worry about sanitizing HTML with Clearwater or React. It's not that "it's sanitized for you" (which I've heard people say a lot); it's that the parser is never even invoked.
Instead, our intermediate representation is a JS object which has properties that mirror what the actual DOM node's will. Copying this to a real DOM node is trivial. The advantage that the HTML-parsing method has here is that it can be done in native code rather than through the JS API.
The part where replacing HTML really bogs down is in rendering. Removing all those DOM nodes and regenerating them from scratch is not cheap when you have a lot of them. When very little actually changes in the DOM (Nate's example was adding an item to a todo list, so the net change is that one li and its children get added to the DOM), you're doing all that work for nothing. All CSS rules, styles, and layouts have to be recalculated instead of being able to reuse most of them.
Even with persistent data structures (data structures that return a new version of themselves with the requested changes rather than modifying themselves internally), when you add an item to an array, you are only using a new container. All the elements in the array are the exact same objects in memory as the previous version. This is why persistent data structures are still fast, despite occurring in O(n) time. If it had to duplicate the elements (and all the objects they point to, recursively), it would be so slow as to be unusable if you had to do it frequently.
Injecting a nearly identical DOM tree is exactly that. It generates entirely new objects all the way down. We had exactly this problem at OrderUp before moving our real-time delivery dashboard from Backbone/Marionette to React.
The Benchmark
I built a primitive blog-style app using Rails 5.0.0.beta3 that generates 2000 articles using the faker gem and added routes for a Turbolinks version and a Clearwater app. I then clicked around both. Here's what I found:
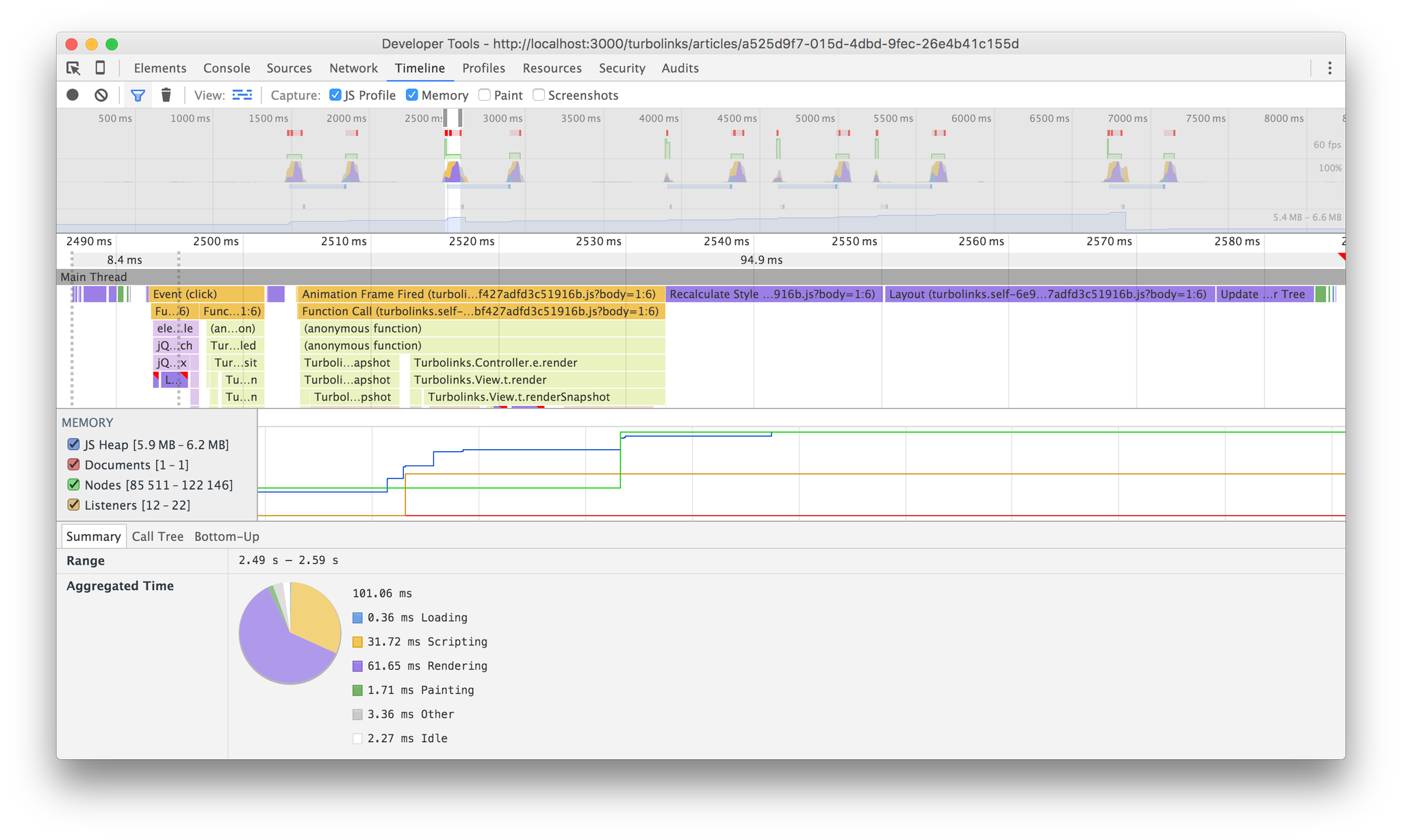
Turbolinks took 101ms, 62ms of which was rendering. I'm not sure why it had to execute JS for 32ms, but it did. I even helped Turbolinks out here by not including the major GC run that occurred on every single render. I only mention it here to acknowledge that it did happen.
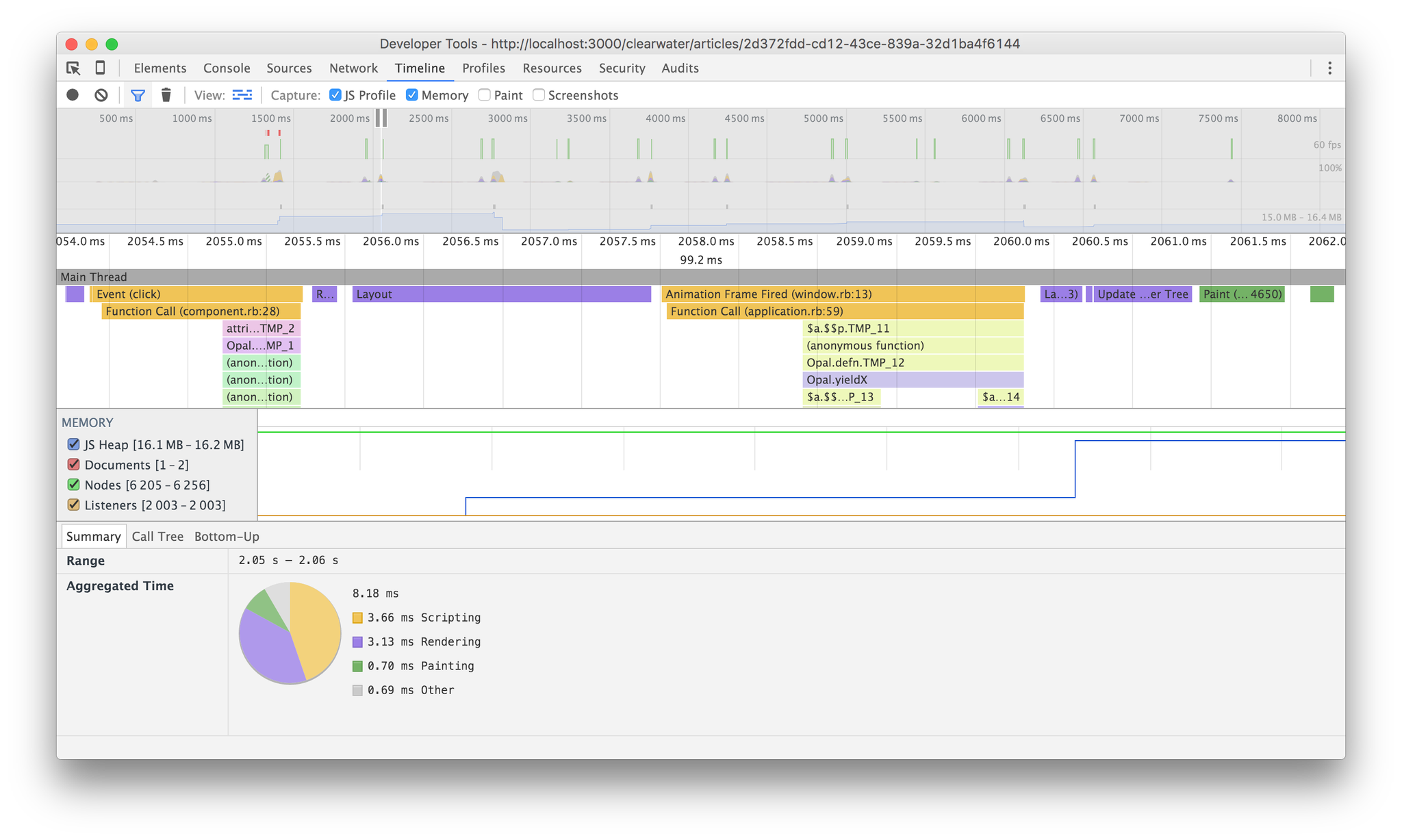
Clearwater took 8ms. Not 8ms of JS. Not 8ms of rendering and style calculation. Just 8ms. From the link click to the final paint on the screen, it executed 4x as fast as Turbolinks' JS and nearly 8x as fast as it could render to the DOM. Overall, it is an order of magnitude faster than the Turbolinks version, despite rendering inside the browser. This is huge on an old/low-spec device — the same devices Nate advised using Turbolinks for.
Using intelligent caching is what allows it to perform so quickly. All I did was use a cached version of the articles list if the articles array was the same array as before.
Partial Replacement Support?
Nate did mention that Turbolinks 5 does not "yet" support partial replacement, so maybe that will be implemented and it won't have to blow away the entire DOM, but the coupling I noticed in the README for Turbolinks 3 between the controller and the rendered HTML was a little off-putting. It seems like a weird server-side Backbone thing. Note that there is no release of Turbolinks 3, though.
Celso Fernandez also pointed out that the Turbolinks README contains a section explaining that partial replacement was intentionally removed from Turbolinks 5, so it looks like this performance won't improve in Rails 5.


