B'more on Rails Attendance
Tonight was a massive turnout at the talk night for B'more on Rails, one of the meetup groups I co-organize. When the group was first created on meetup.com, the original organizers put an arbitrary limit of 65 attendees at the meetup, thinking it'd probably never be reached. Tonight, we not only reached that, but we had at least 18 people on a waiting list.
This is due in large part to Natasha Jones' Workshop for Women last month. Women from that workshop accounted for over a quarter of the attendees tonight, and half of Hack Night a few weeks ago (Talk Night is the 2nd Tuesday of the month, Hack Night is the 4th Tuesday).
We also had a pretty impressive attendance from Towson University — two professors and close to a dozen students. And another professor from another university in Baltimore. There are probably a half dozen universities with a footprint in the city and he didn't specify, so I don't know which one.
One of the things that made me happiest about it was that even with that many people there, it wasn't a giant mess of white dudes. There were definitely some there, but I'd estimate they (well, I suppose "we" is more accurate, considering I'm a white guy) were only 25-30%, tops. Considering that that percentage is usually at least 75%, this was a refreshing change. I love knowing that the outreach that we've been doing has been working!
In fact, two of the three presenters tonight were women of color. They gave presentations that were perfect for the audience we had tonight. Vaidehi Joshi talked about state machines (a preview of her Ruby on Ales talk) and Ashley Jean talked about password hashing with BCrypt — her first tech talk ever. I spoke to several people who attended who were still very new to programming and they said they got a lot out of both talks, which is fantastic when you consider that neither of those are beginner-level topics.
As you can probably tell, I'm bursting with excitement and happiness at how well this meetup went. This is despite the fact that there were so many people there that we ran out of seats and the temperature inside the room was 10° higher than it was outside it.
It was something that we learned very quickly we weren't setup for logistically, though. We only barely had room for everyone, so we may need to lower that 65-person limit. We also had no idea how much food to buy for that many people (we way overshot it) and it's a little awkward to tell sponsors "oh, by the way, the food bill is probably going to be 2-3x higher for the foreseeable future, especially until we can figure out how much food to get for this crowd". :-)
Turbolinks vs the Virtual DOM
On Friday, Nate Berkopec tweeted out:
Side effect of the Turbolinks-enabled mobile app approach - guaranteed to be fast on old/low-spec devices b/c the Javascript is so simple. — @nateberkopec
Think about the operational complexity of React versus Turbolinks. An entire virtual DOM versus "$('body').innerHTML(someAjaxResponse)". — @nateberkopec
He justified his hypothesis by showing that the Ember TodoMVC takes 4x as long to update as a Turbolinks version, which I found odd because his original claim was about virtual DOMs, but the Ember TodoMVC uses an old version of Ember that doesn't use a virtual DOM — Ember's virtual DOM, called Glimmer, didn't appear until 2.0. It injects HTML, exactly what Turbolinks does. The only difference is that that HTML is generated by the browser. It trades a round trip to the server for CPU usage on the client.
Having spent the last year or so studying the performance advantages and disadvantages of virtual-DOM implementations and trying to ensure that Clearwater is fast enough for any app you want to write (including outperforming React), I had a sneaking suspicion that Turbolinks would not be faster than a virtual DOM that uses intelligent caching. I base that on the way HTML rendering in a browser works. This is kinda how node.innerHTML = html works in JS:
- Parse HTML, find tags, text nodes, etc.
- Generate DOM nodes for each of those tags and wire them together into the same structure represented in the HTML
- Remove the existing nodes from the rendered DOM tree
- Replace the removed nodes with the newly generated nodes
- Match CSS rules to each DOM node to determine styles
- Determine layout based on those styles
- Paint to the screen
With a virtual DOM, there is no HTML parsing at all. This is why you never have to worry about sanitizing HTML with Clearwater or React. It's not that "it's sanitized for you" (which I've heard people say a lot); it's that the parser is never even invoked.
Instead, our intermediate representation is a JS object which has properties that mirror what the actual DOM node's will. Copying this to a real DOM node is trivial. The advantage that the HTML-parsing method has here is that it can be done in native code rather than through the JS API.
The part where replacing HTML really bogs down is in rendering. Removing all those DOM nodes and regenerating them from scratch is not cheap when you have a lot of them. When very little actually changes in the DOM (Nate's example was adding an item to a todo list, so the net change is that one li and its children get added to the DOM), you're doing all that work for nothing. All CSS rules, styles, and layouts have to be recalculated instead of being able to reuse most of them.
Even with persistent data structures (data structures that return a new version of themselves with the requested changes rather than modifying themselves internally), when you add an item to an array, you are only using a new container. All the elements in the array are the exact same objects in memory as the previous version. This is why persistent data structures are still fast, despite occurring in O(n) time. If it had to duplicate the elements (and all the objects they point to, recursively), it would be so slow as to be unusable if you had to do it frequently.
Injecting a nearly identical DOM tree is exactly that. It generates entirely new objects all the way down. We had exactly this problem at OrderUp before moving our real-time delivery dashboard from Backbone/Marionette to React.
The Benchmark
I built a primitive blog-style app using Rails 5.0.0.beta3 that generates 2000 articles using the faker gem and added routes for a Turbolinks version and a Clearwater app. I then clicked around both. Here's what I found:
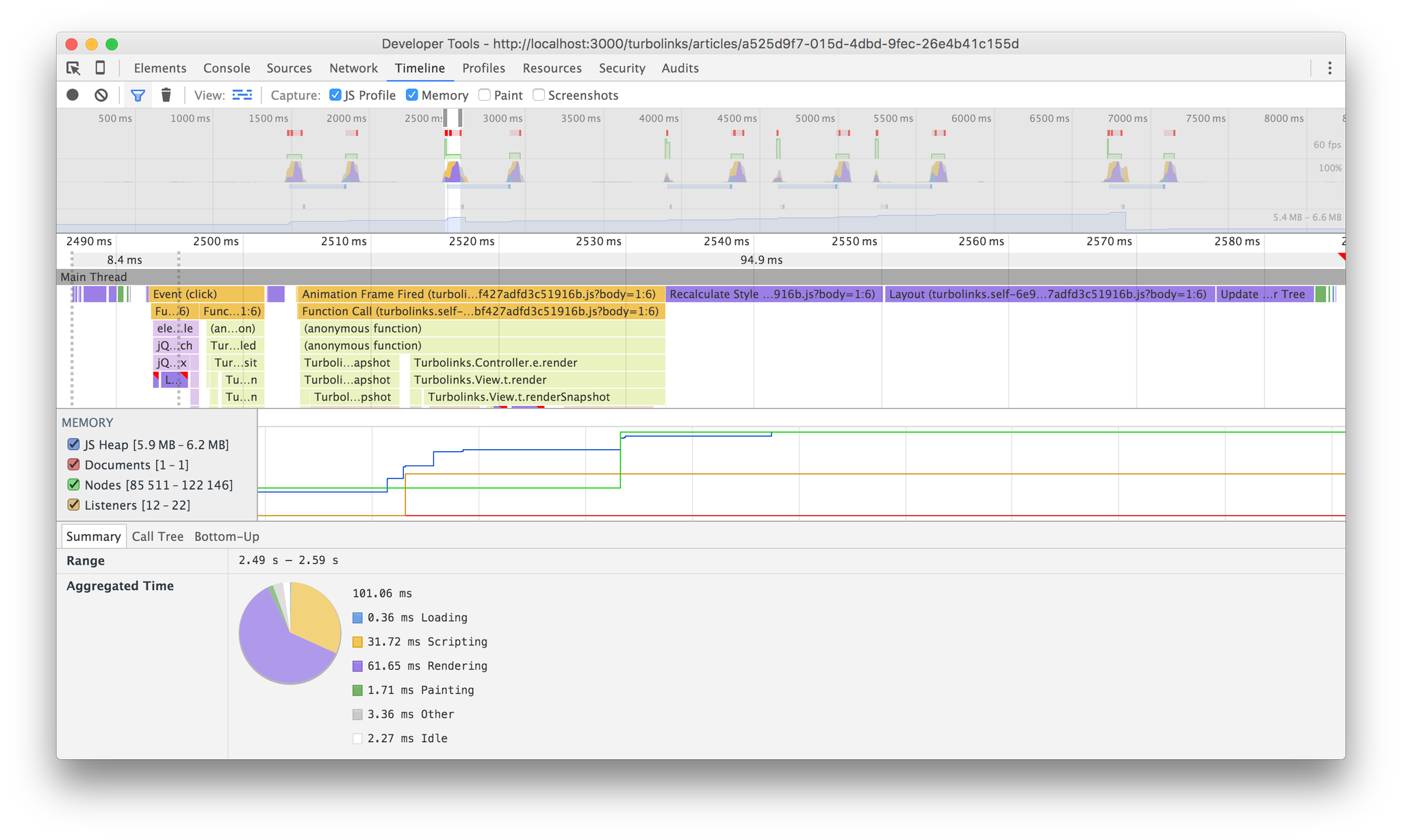
Turbolinks took 101ms, 62ms of which was rendering. I'm not sure why it had to execute JS for 32ms, but it did. I even helped Turbolinks out here by not including the major GC run that occurred on every single render. I only mention it here to acknowledge that it did happen.
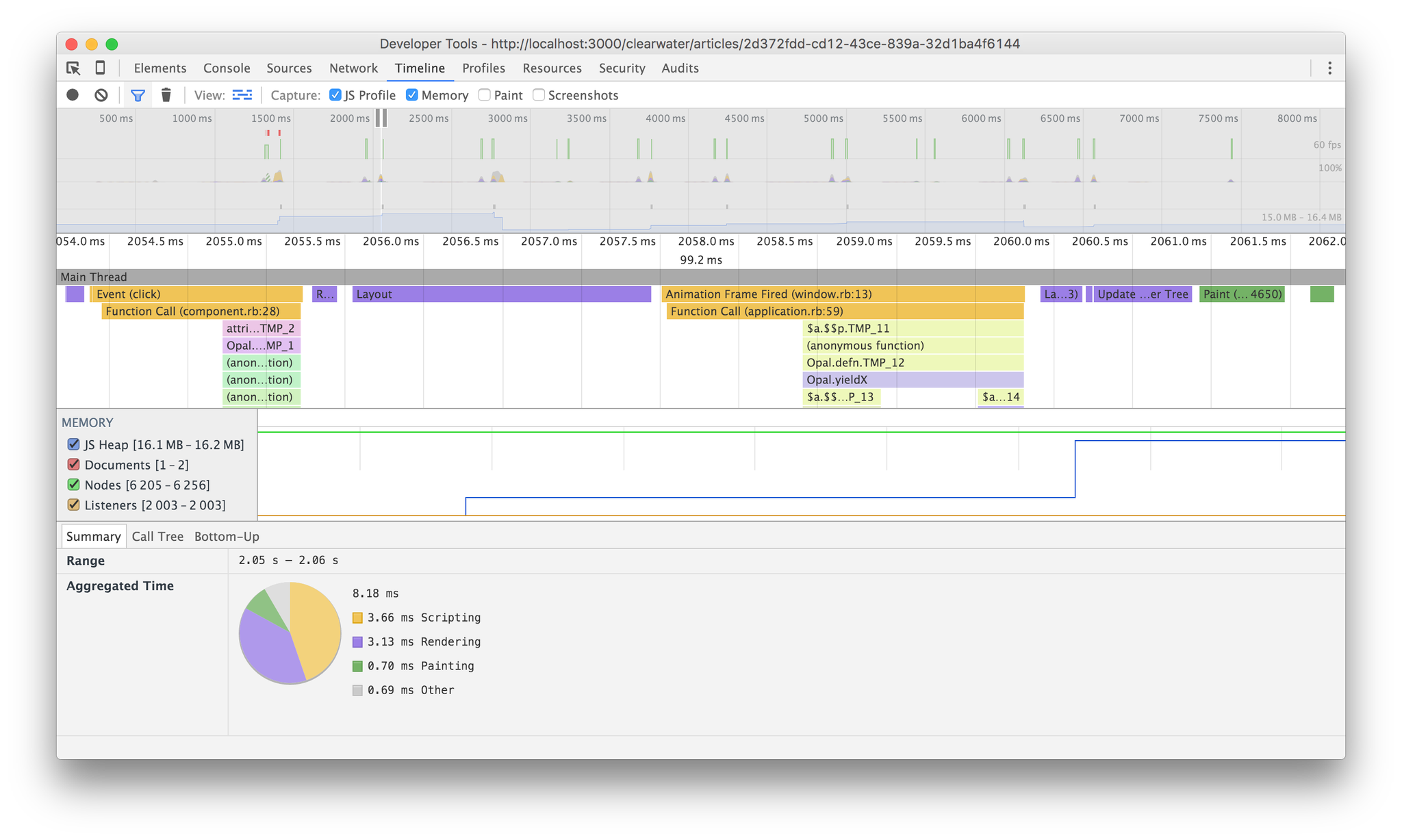
Clearwater took 8ms. Not 8ms of JS. Not 8ms of rendering and style calculation. Just 8ms. From the link click to the final paint on the screen, it executed 4x as fast as Turbolinks' JS and nearly 8x as fast as it could render to the DOM. Overall, it is an order of magnitude faster than the Turbolinks version, despite rendering inside the browser. This is huge on an old/low-spec device — the same devices Nate advised using Turbolinks for.
Using intelligent caching is what allows it to perform so quickly. All I did was use a cached version of the articles list if the articles array was the same array as before.
Partial Replacement Support?
Nate did mention that Turbolinks 5 does not "yet" support partial replacement, so maybe that will be implemented and it won't have to blow away the entire DOM, but the coupling I noticed in the README for Turbolinks 3 between the controller and the rendered HTML was a little off-putting. It seems like a weird server-side Backbone thing. Note that there is no release of Turbolinks 3, though.
Celso Fernandez also pointed out that the Turbolinks README contains a section explaining that partial replacement was intentionally removed from Turbolinks 5, so it looks like this performance won't improve in Rails 5.
Clearwater Pending Projects
I have been working on a lot of things with Clearwater, but I haven't been talking about it publicly as much as I would like. I'm sorry about that.
Here is a list of things I've gotten working well for Clearwater that are as yet unreleased:
- Server rendering
- Hot loading in development (updating running code without refreshing the page)
- Trimmed-down JS payload
- Referencing rendered DOM nodes
And there's more that I want to do:
- Documentation
- Screencasts
Server Rendering
Rendering a client-side app on the server is a hot topic. People want it for a few reasons, namely SEO and faster content delivery. There is an open pull request for it that I'm working on trying to get to a good point to merge in.
The performance impact of server rendering a Clearwater app is unnoticeable. For comparison, when server-rendering a React app with react-rails, the performance impact is immense. I've yet to see a Clearwater app take longer than 2ms to render server-side (that is, if you were passing serialized models to the client with gon or some similar implementation already to remove the need to fetch models after the app initializes, the difference in render times will be that trivial). I recommend trying it out with your app:
gem 'clearwater', github: 'clearwater-rb/clearwater', branch: 'server-render'
Hot loading in development
I've written a gem called clearwater-hot_loader (not yet released) that you can run on the server in development. It checks for changes to Ruby files in your app/assets and assets folders by default (in the case of Rails and Roda), then compiles them and pushes them to the browser over a websocket connection.
On the client side, this is all you need to make that work:
require 'clearwater/hot_loader`
This sets up the websocket, listens for changes, evaluates the updated code and re-renders any Clearwater apps mounted into the document. When figuring out styles and copy, this has been a wonderful time saver.
Trimmed-down JS payload
In Clearwater 0.3.1 and below, we use the opal-browser gem as the DOM abstraction. It was helpful in getting Clearwater going in the beginning, but it compiles to a massive JavaScript payload. The worst part is that about 90% of that code will never get executed in most Clearwater apps.
I wrote a gem called bowser, which provides the minimum DOM API needed to get most Clearwater apps going. It supports DOM elements, DOM events, setTimeout, setInterval, and requestAnimationFrame (this one is also used internally by Clearwater to coalesce renders). It also includes optional AJAX support if you require 'bowser/http'.
Before this change, one of my apps was 122KB minified and gzipped. Afterward, it was 83KB. This also reduced the number of assets from over 200 to about 70, dropping page-load times in development from 2-2.5 seconds down to well below 1 second.
This change has been merged into the master branch, but there hasn't been a gem release for it yet.
Referencing rendered DOM nodes
Using a virtual-DOM can make it difficult to get access to the rendered DOM nodes, but you may need them for a few different reasons. Here are the examples that I can think of just off the top of my head
- Getting form input values
- Using a third-party JS library that renders itself into an existing DOM node, like a Google Map, which requires you to own the rendering/updating of that node
Form inputs
I usually use the grand_central gem (disclosure: I wrote that, too) to manage my app state — which includes the values of most form inputs. However, we don't want to assume everyone's doing that. If you're not storing input values in some object that persists between renders, how do you do something like this?
def render
form({ onsubmit: method(:handle_submit) }, [
input(type: :email, placeholder: 'Email'),
input(type: :password, placeholder: 'Password'),
input(type: :submit, value: 'Login'),
])
end
How would you get the values of the email and password fields in this form in the onsubmit handler? You would need access to the input fields to figure that out.
Well, this can be done by giving the virtual-DOM node a Clearwater::DOMReference object:
require 'clearwater/component'
require 'clearwater/dom_reference'
class LoginForm
include Clearwater::Component
def initialize
@email_field = Clearwater::DOMReference.new
@password_field = Clearwater::DOMReference.new
end
def render
form({ onsubmit: method(:handle_submit), [
# Notice the dom_ref attribute here
input(type: :email, dom_ref: @email_field),
input(type: :password, dom_ref: @password_field),
input(type: :submit, value: 'Login'),
])
end
def handle_submit event
event.prevent
# Calling .value on the DOMReference objects gives the input value
email = @email_field.value
password = @password_field.value
# ...
end
end
This feature hasn't been merged into master because I'm still testing it, but it's worked pretty well so far and should make it in soon.
Owning the node
Sometimes instead of just getting a reference of a DOM node, you need to own that node's contents. For example, you may not be rendering HTML-like content to it. You may be using a Google Map, which is updated by using API calls instead.
To accomplish this, we need to be able to tell the virtual-DOM engine to let us handle this node. We can do this using the Clearwater::BlackBoxNode mixin:
require 'clearwater/black_box_node'
class MapContainer
# Notice we don't include Clearwater::Component here
include Clearwater::BlackBoxNode
# The definition of the node you want to use for this one.
# It defaults to a blank div.
def node
Clearwater::Component.div(
style: {
width: '50%',
height: '600px',
}
)
end
# This method is called when this object is first mounted into the DOM. Use this
# to set up event listeners, render a map, etc.
def mount(node)
# node is the DOM node as a Bowser::Element
Bowser.window.animation_frame do
# do a Google Map thing in here. We need to wait until the next animation
# frame because this actually gets called before the page reflow and GMaps
# requires that this DOM node be within the rendered document.
end
end
# Use this method to copy over or calculate new state from the previous instance
# and update the DOM node.
def update(previous, node)
# previous is our previous instance
# node is our DOM node, just as in the mount method
end
# unmount is called when this object is removed from the generated virtual-DOM
# tree during the diff/patch process. Use this to remove event listeners, etc.
def unmount(node)
# ...
end
end
This is also not merged yet until I am sure it works the way we need it to.
Documentation
I've begun work on a documentation site (using Clearwater, because of course I am), but I'm not actually that good at writing docs. I get too caught-up in the minutiae.
If someone else would like to help write docs, please feel free to contact me. You don't need to be an expert. I'll work with you on the docs; I'm just bad at doing it alone. :-)
Screencasts
I've been wanting to work on screencasts, but it's difficult at the moment. Recording and editing video is a time-consuming process. Turns out there's a reason professional screencasters only release 1-2 videos a week. :-)
I might just do a few live recordings with no editing (except maybe automatic noise reduction because that's a single click in iMovie) just to get something going.
Conclusion
Clearwater development is still pretty hot, even though I haven't been talking about it as much as I would prefer.
I'm planning on releasing a 1.0 beta when some of these are ready — especially the documentation. I want people to realize that Clearwater is not just a toy framework I play with in my spare time. I've introduced it at work as a way to improve frame rates in our most performance-intensive app. I've tested nearly every React experiment I've seen in the wild (still working on Ryan Florence's MagicMove, though) and they were all easier to write in Ruby.
How you can help:
- Contribute documentation, even if it's just a page on the project wiki … which doesn't really exist yet but you can help with that, too! ;-)
- Ask questions — this is about the most important thing. If you don't understand something about Clearwater, I won't know if you don't tell me. :-) Because I have very intimate knowledge about how Clearwater works, I may not realize that someone who isn't me is having trouble understanding certain concepts. It's okay not to understand something when you're used to a different web-development style.
- Provide feedback using GitHub issues.
And if nothing else, you'd be surprised at the level of encouragement that a single tweet can provide.
Going back to my first React app
When I first learned about React, I thought it was such an amazing tool. It made everything so much easier. I still think it's pretty great, but when I went back to the first React app I wrote for work, I realized just how little I understood about using it.
Components stay mounted
One of the most important things I didn't understand was that each DOM node represented by a component has a 1:1 relationship with that component. This means that, as long as that DOM node sticks around (there isn't a node of a different type rendered in its place and it isn't removed entirely), React will use the same component instance for it forever.
This particular app was for ops managers in each market to coordinate delivery schedules with drivers. That's all it did, so the content never changed structure much. This means that the components we used, for the most part, stuck around for the life of the app.
We decided to keep a lot of the data in component state because the app itself was simple. Each block of time on the schedule had some metadata on it, like the number of drivers we needed to be available and the minimum amount the driver would make for being available for deliveries (in case their commissions + tips don't reach that value) for that time segment. Since props are meant to be immutable and we needed to be able to modify some of this data, we simply moved the props to state using getInitialState
The problem is that, when adding a new feature, after days of screwing around trying to figure out why something continued to render stale state, I realized that getInitialState wasn't being called. Turns out, it is called when the component is mounted and then it will never be called again on that component. This makes perfect sense, but is confusing if the lifecycle of a component doesn't match what you think it is. At the time, we thought we'd be getting new components on each render. Somehow, this didn't cause any problems until we began adding new features to it last week.
Once I realized what the problem was, I began iterating on it to make it easier to work with, but I just succeeded in making more of a mess. First, I tried using componentWillReceiveProps to take the new props and update the state — something like this:
ScheduleHeader = React.createClass
# ...
getInitialState: -> @props
componentWilReceiveProps: (nextProps) -> @setState nextProps
But this resulted in consecutive renders (componentWillReceiveProps is caused by a render, then we call setState which starts another one) and it didn't work as well as I thought it would. Then I tried bypassing setState and just using this.state = nextProps inside componentWillReceiveProps. This wasn't any better.
I tried several other equally shortsighted approaches, everything I could think of to make it possible to work with the component in the way it was currently implemented. But it just ended up fixing one bug and causing another. This entire schedule header needed to be gutted. And then, because of the way the header worked with the body of the schedule, it also meant that we needed to do the same there. I was so discouraged I had to go ask Kyle, the one who originally paired with me to write it (we were both learning React together), to help me out.
The good news is that Kyle is one of those developers who never seems to get discouraged by things like this. We ended up rewriting most of the header components (and changing the structure of ones we didn't rewrite) to use state stored in a Redux store, but we got that nearly done in just a few hours.
The lesson here is that, when people recite the React mantra "prefer props over state", this is one of the reasons why. Your component will receive new props on every render, but it might not receive new state because getInitialState will only be called once since it gets reused on the next render.
Component structure can be deceiving
One of the ways we organized our components originally was that each header field determined on its own whether it would render text or a form input to modify its value. I don't have the code in front of me, but it was something like this:
NeededDriverCount = React.createClass
render: ->
if @state.editing
# The EditField component takes all the data needed to perform an AJAX request.
<EditField
updateUrl={"/path/to/model/#{@props.model}"}
attribute="neededDrivers"
modelType="myModel"
defaultValue={@props.model.neededDrivers}
/>
else if @state.saving
<div>Saving…</div>
else
<div>{@props.model.neededDrivers}</div>
And then I did the same for the other attributes. Each attribute had its own component that did almost the same goddamn thing. So. Much. Duplication.
We ended up refactoring that into a single component that did the same thing for each field, where we could just pass a value and a callback:
ScheduleHeaderHour = React.createClass
render: ->
# ...
<EditableField
value={model.neededDrivers}
onUpdate={api.updateNeededDrivers}
/>
The EditableField only needs to know the value it's displaying or editing (which one is rendered is based on its own internal state) and a function call when the user presses Enter while editing. That's it! I had originally tried to make the EditField too smart in some ways and not smart enough in others; it constructed its own AJAX request but didn't determine whether it was displaying text or an input. The EditableField component does the opposite: it determines what to display but lets an api object actually update the model on the server.
This refactoring was simple mechanically, but it put everything in the right place conceptually. Sometimes, the way you name things has a lot of influence on how you work with them.
Opal and Transphobia
Today, Coraline Ada Ehmke, a respected developer in the Ruby community, posted an GitHub issue on the GitHub repository for the Opal project, a Ruby-to-JavaScript compiler. The TL;DR of the issue is "one of the project's core members has posted transphobic tweets; he should be removed."
If you've spoken to me about programming over the past several months, there is a high probability that you know about my love for Opal, stemming from my love for Ruby and my lack thereof for JavaScript, which I also do not try to hide. I wrote the Clearwater web framework with Opal because I love using it that much. I've spoken about it at the B'more on Rails meetup in Baltimore twice now; the first time was in January 2014 about how great Opal is and again in January 2015 when I announced Clearwater. I talked about it at RubyNation just last week. Opal makes front-end development enjoyable for me like nothing else does.
I bring that up because when I tell you that I'm fucking furious at how the Opal team handled Coraline's GitHub issue, I want you to understand all that that implies. Seriously, it's fucking horse shit.
If you read the first response from an Opal core member — whom I know only as "meh" — he dismisses her in about the most insulting way I can think of. He then proceeded to defend his actions throughout the thread.
Admittedly, the title of Coraline's original post toes the line of feeling like dictating who should be on the project's team. However, the body of the post reads more as "hey, you might wanna reevaluate your team". That easily overrides the initial visceral response I had to the title.
I understand the desire to defend yourself in his situation. Whenever someone calls me out for doing something stupid like that (as a cisgender, straight, white man, it's not unheard of for me to overlook my own privilege), it's my first reaction, too. But I also understand how that makes people feel, so rather than act on those defensive impulses, people need to realize maybe they should have a look at what they're doing that might not be in everyone's best interests.
Even if he had posted the dismissive, insulting comment and come back later saying "I'm sorry, I got defensive. I rushed to Elia's defense because he's my friend. I should not have said that.", maybe Coraline wouldn't think any better of him (or the Opal project) — the insult was directed at her, after all — but it might have gone a long way to mitigate the damage he caused in the eyes of the community.
What about Clearwater?
My friend Kurtis expressed interest in Clearwater a while back and I invited him to work on it with me. It's the reason the repository has moved to the clearwater-rb organization. If he had done what meh did today, I would've dropped him from the organization.
Instead, though, he wrote a fantastic article about how Clearwater supports trans developers. I don't want to detract from it so I won't try to TL;DR it here. Please, check it out. It's not long and you've already gotten this far through this one.
A ray of hope
At the time this all went down, I was at the hospital with my mother, so I didn't have much time to contribute to the conversation until well after the damage was done. Once I got home, though, I opened up my laptop to check on the situation and saw this GitHub comment from Adam Beynon, the creator of Opal:

In response to meh and others who are under the impression that a project has no beliefs or feelings toward any particular subject, he had this to say:

This give me some hope here. I was afraid it'd be too little too late, but he's actively pursuing the code of conduct, which will help define what to expect in situations like this moving forward. Adam created Opal; he has full control of the project and has the power to make this right.
Please, Adam. Please make it right.
Acknowledgements
Thank you to Betsy, who brought this to my attention first. I met Betsy at RubyNation and she was easily one of the most interesting people there (and she wasn't even the one who brought robots). She also spoke up to meh in the GitHub thread.
Thank you to Kurtis for writing that blog post. He wrote it without even talking to me about it. I knew I could trust him completely on issues like this. He is a strong LGBTQ advocate, stronger than I could ever be. His tweets to Elia are a big reason this got so much attention.
Thank you to Coraline, whom I haven't had the chance to meet but who does amazing things for LGBTQ and other marginalized people in tech. Given the great things I've heard from people who have met her, I'm missing out.
Thank you to Nikki Murray, who sent me messages of encouragement through this, letting me know she still thinks my project is great. Considering she likely hadn't ever used Opal before goofing around with Clearwater last weekend, that's huge to me.
Thank you to Adam Beynon for stepping in and doing the right thing — not for his project, but for the members of the community.
And if you're not one of the people I mentioned above, I still appreciate you for reading this all the way through. I know saying that is like the trophy kids get for showing up, but you didn't have to show up here. You chose to. That's important to me.


