Clearwater and the Virtual DOM
I've been experimenting with a lot of things in Clearwater since I first introduced it at B'more on Rails. The reason I showed it to people was because I was hoping to get people talking about front-end development in Ruby with Opal (I've also given a presentation about Opal at B'more on Rails). One of the things that Clearwater does on every link click, at the moment, is rerender the entire app. It does it with a single call, so it's not rendering chunks of HTML here and there, so it's not the worst performance in the world, but I did notice it was clobbering input fields, and micromanaging event handlers (for individually rendered views and attribute-bound blocks) has been a nightmare.
Experiment #1: Components with templates
Components are an interesting way of thinking about web development. Having all of your functionality
One of my experiments has been with adding components to Clearwater. These are Ember-style components rather than React-style, so they still have templates. They're basically a controller and a view in one, and unlike controllers and views, which are instantiated once, the components were designed to be disposable, so you could do something like this in your Slim templates:
ul#todos
- todos.each do |todo|
= TodoComponent.new(todo: todo)
But these components have a weird caveat: anything that has events associated with it (basically, anything interactive) needs to let the renderer know about them, so everything from the top of the render tree all the way down has to pass along a reference to the renderer. You had to do this by passing the view's renderer into the component:
= TodoComponent.new(todo: todo, renderer: renderer)
I've got a few ideas on how to make it better, but for the moment it's just a bit awkward (especially if you're using a bunch of different components in a single view) and it doesn't fix the problem of clobbering the DOM on every link click.
Also, having a lot of small components, each with their own template, means that there's a cost to adding them to your project. Not only do you have to create two files (implementation and template) for each of those components, but each template has to be required into your app, so there's a significant amount of headspace involved.
Experiment #2: Compiling Slim to React
Virtual DOM implementations have become a pretty hot topic lately. First, React shook everything up with their virtual DOM implementation and the idea of just rerendering the entire app any time there's a change. Now, Ember's doing something similar with their new Glimmer engine. I decided to try to use React as the view layer for Clearwater by compiling Slim to React components instead of HTML.
The slim gem depends on a template-compilation gem called temple, which allows you to set up a pipeline where each step in the pipeline takes care of a specific portion of the compilation. What I did was take a Slim::Engine, remove the parts of that pipeline that generate HTML and instead use my own filters to generate React code.
This kinda worked. There were a few challenges and I never quite overcame them. I also realized that React provides a lot more than I need. All I wanted was the virtual DOM. I eventually abandoned this experiment.
Experiment #3: Virtual DOM, no templates
My latest experiment has been using a virtual DOM library, wrapping it with Opal. Initial experiments have been great and I'm currently working on including it into Clearwater.
I realized that this approach would be difficult because I would have the same trouble with converting Slim to virtual-DOM nodes as I did with React, so I decided I'd try it without Slim at all, and just include a DSL for elements:
class TodoList
include Clearwater::Component
def initialize(todos)
@todos = todos
end
def render
div({id: 'todo-list'}, [
h1(nil, 'Todos'),
ul({class_name: 'todo-list'},
@todos.map { |t| Todo.new(t) }
),
])
end
end
It seems to work really well in my own projects so far, so I've opened a PR on the repo's new home (notice the shiny-new clearwater-rb organization) to encourage conversation about it.
I haven't merged it in yet because it changes how Clearwater renders in a way I haven't found to be backwards-compatible. I'm sure it could be done, but it would require a bunch of work I didn't feel like doing at the time. I wanted to get some feedback from others before I merge it in. Also, I'm not quite done with it.
The virtual-DOM library has a few extra features that I'd like to support, as well, like selective rendering (similar to React's shouldUpdateComponent() function). Clearwater's virtual-DOM support will get there, and once it does, I expect it to be amazing. :-)
Five Stages of Programming Grief
- Denial — There's no way this feature could be broken!
- Anger — Ugh! Who wrote this code?!
- Bargaining — Alright, I'll work on it if you buy me coffee/pizza/beer
- Depression — I can't figure this out. I'm the worst programmer EVER!
- Acceptance — Well, it kinda works now. SHIP IT!
Gentle Migration from Marionette to React
Backbone.js provides a pretty great model layer for front-end web applications, but a lot of the rendering is still DIY. At OrderUp, we've been using Marionette on top of Backbone to handle our rendering in the customer-facing app as well as several internal apps. All was well, we worked out some good usage patterns that kept us productive and the code from becoming spaghettiesque.
My colleague Kyle Fritz developed a new dispatcher to allow us to monitor orders in multiple markets (market = one of the various cities in which we operate) simultaneously. Our original dispatcher could only handle one market at a time, so this was a huge deal for our support team who had to jump around between these markets for every call, email, or customer chat.
To understand what all this entails, I'll go into a few details. First, this app monitors everything in real time, so every time an order comes in or a driver makes themselves available/unavailable for deliveries or updates their location or the status of a delivery ("on my way to pick up the food", "on my way to the customer", etc), we send it to Pusher. The Marionette views in the dispatcher monitored all of these Pusher channels and updated the display whenever any of the underlying models changed.
Spoiler alert: the DOM is slow
Marionette made the development of this new, more powerful dispatcher pretty simple, but it had one major problem: at dinnertime when orders were coming in hot and driver/delivery statuses were getting updated like crazy from hundreds of drivers in multiple markets, all the constant DOM updates were pushing our support team's browsers to the limit.
Kyle and I tried a lot of different tactics to throttle these updates but we couldn't get more than a few percent out of it. We went ahead and opened up a profiler and had a look. Because every Pusher update triggered a DOM update, 80-90% of the time was spent doing this. At peak times, rendering even some of those tiny DOM elements (many of these views were a single <span> tag) was taking longer than we could afford to spend before the next message came in from Pusher.
Maybe Marionette isn't the right tool for this job?
Coincidentally, we had both been learning and playing with React recently. We had already written a new UI for market managers to schedule drivers with it to get our feet wet.
Since React is known for its extremely efficient rendering through laser-focused, coalesced DOM updates, I threw out the idea of rewriting the app with it. Kyle's response was a mix of "that'd be cool" and "I really don't want to rewrite this whole fucking thing."
It then hit me that Marionette views and React components had something in common: their entire operation hinges on the render method. This gave me an idea. What if we replaced some of the bottlenecked Marionette views with React components? Neither of us had any idea if it'd work, so we gave it a shot.
Step 1: Marionette views become React components
One of the biggest bottlenecks the profiler showed was rendering the lists of orders in each market, so we tackled that first.
We took our Order view, did a quick port of its .eco template to .jsx (primarily a matter of converting <%= @foo %> to {@state.foo}), stuffed that in the render method and converted it from Marionette.LayoutView to a React.createClass:
class Views.Order extends Marionette.LayoutView
tagName: 'tbody'
className: 'order'
template: App.JST('orders/templates/order')
events:
'click': 'showOrderPopover'
onDestroy: => # ...
onRender: => # ...
# etc...
… became …
Order = React.createClass
render: ->
# JSX content (what was previously the .eco template) goes here
componentDidMount: -> # was onRender
componentWillUnmount: -> # was onDestroy
handleClick: -> # was showOrderPopover, the click handler in the Marionette view
Notice the onDestroy and onRender callbacks from Marionette had direct React analogs in the form of the componentDidMount and componentWillUnmount methods.
Step 2: Rinse and repeat as high as necessary up the DOM
We did a similar conversion for the Orders view which contains each of the orders. The main difference was that Orders now also mixes in Backbone.React.Component.mixin to help Backbone and React work together. According to the README for this library, this mixin will need to be included in your top-level React component.
Step 3: Make container view render the React components
Then to kick off all of the rendering, we replaced the view that contains this section of the dispatcher with this:
class Views.OrdersList extends Backbone.View
initialize: (@options) ->
render: =>
React.render
<Orders
collection={@collection}
trigger={@trigger.bind(@)} />
@el
@ # Backbone views must return `this`.
We used a simple Backbone view because all we cared about was the render method. Once the OrdersList was rendered, it went ahead and rendered the Orders component into its element, which rendered each Order component based on its @collection attribute.
One suspenseful page reload later and, to our amazement, nearly everything worked.
Notice the collection and trigger attributes we passed into Orders. The reason we passed the collection should be obvious if you're familiar with Backbone, but trigger may not be. Some of the functionality of the dispatcher relied on bubbling events up the view hierarchy, so we still needed to call Backbone's trigger method to bubble those events up.
How'd it do?
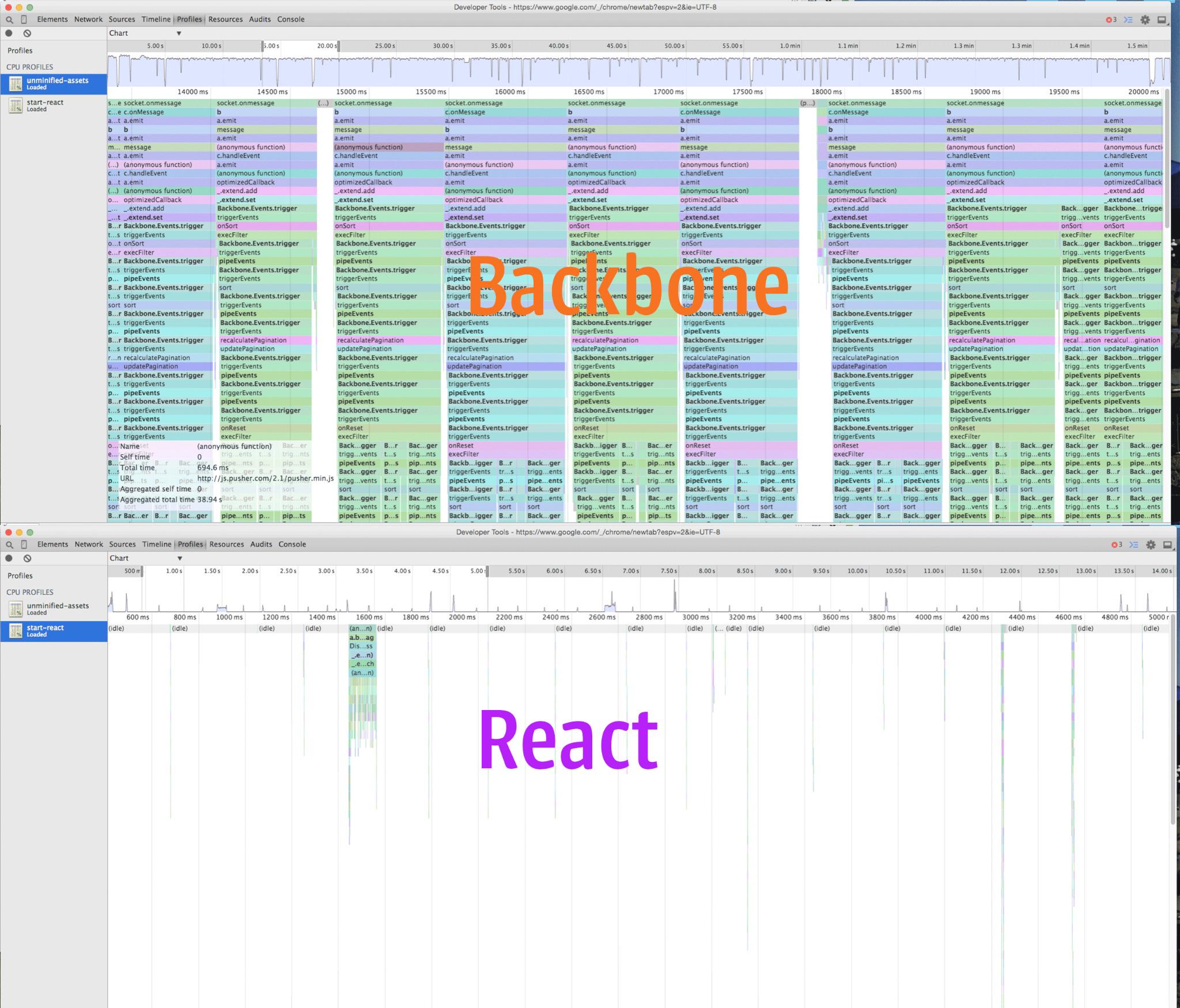
With Marionette, the Pusher events were happening faster than the DOM updates and the browser couldn't keep up. You can see from that graph that there was almost no idle time. Those events were pegging the CPU so much that even scrolling was impossible sometimes.
We repeated this process on a couple other hot spots in the dispatcher with results that were slightly less spectacular but no less important during our peak hours.
Even on Super Bowl Sunday, easily one of our biggest nights of the year, our new React-based dispatcher handled it like a champ. Given that the Marionette-based one was struggling on an average weeknight, I can't imagine it would've been usable at all that night.
How long did it take?
The majority of the work happened in just a few hours. The React-based dispatcher was deployed to production on the same day we started.
Kyle and I were both amazed at how easily and smoothly we were able to move parts of it from one to the other. We did have a few things to touch up due to event handlers being a bit different between the two, but we didn't spend more than a few days on this total.
So you're saying we should give up on Marionette?
Hell no. Marionette is pretty great at what it does. For most browser apps, the rendering performance is only required to be as fast as the user can navigate the app and, for that, Marionette is just fine. The performance requirement for this specific app wasn't that we had to keep up with a user clicking around the app; it was a data firehose we had to keep up with. React's DOM diffing and coalesced updates could keep up with that.
Clearwater, a Front-End Web Framework in Ruby
Front-end web development is dominated by JavaScript. This makes perfect sense, seeing as JavaScript is the only programming language that all major browsers implement. But some developers, myself included, are much more comfortable, and therefore more productive, in other languages even when they are well-versed in JavaScript.
Ruby's class-based object model makes a lot more sense to me than JavaScript's prototypical object model. The Uniform Access Principle appeals to me, as well. I had played around with Opal a lot for the past year and, over Thanksgiving weekend with some time to kill, I decided to try my hand at implementing a front-end framework entirely in Ruby. It's called Clearwater.
In a matter of days, I had routing and rendering working using Slim templates (via my opal-slim gem). A few more days of development to fix the back/forward button and clicking links with modifier keys as well as a few rendering issues — the usual problems that crop up in single-page apps. I had almost everything that Ember had except two-way data binding (which I don't think I actually want) in less than a week of actual development.
The bonus is that this framework is written entirely in Ruby using Opal. I TDDed it using RSpec (via the opal-rspec gem). I wrote my demo app entirely in Ruby. I used Ruby idioms throughout, including method_missing for proxy objects. Everything I tried works.
I had a lot of help in writing the framework because I didn't have to write my own template language. I was able to leverage the power of existing Ruby template engines like Slim and Haml using thin wrappers to tell Opal to store them inside its Template namespace. They get converted to JavaScript templates via Sprockets so there is no runtime compilation in production the way there is with server-side templates. This has the side effect of not needing to choose Slim over Haml for performance reasons.
How is application formed?
Your app consists of a primary controller (the main controller holding app state) and a router holding a tree of routes.
router = Clearwater::Router.new do
route "foo" => FooController.new do
route "bar" => BarController.new
end
route "baz" => BazController.new
end
MyApp = Clearwater::Application.new(
controller: ApplicationController.new, # This is the default
router: router # Default router is blank
)
The router adjusts the controller structure according to the URL and then calls the primary controller, which renders the controllers all the way down.
Controllers
Controllers hold application state, so when you've loaded or generated a set of objects, storing them as an instance variable will keep them around for the next time that route gets rendered.
They are also the targets for routing. If your URL path is /articles/1, it may invoke your ArticlesController and an ArticleController.
Controllers are associated with views. There is no naming convention so the view must be specified.
class MyController < Clearwater::Controller
view { MyView.new }
end
You don't need to have a named view if your view doesn't do anything besides render a template. You can use an anonymous view instance:
class MyController < Clearwater::Controller
view { Clearwater::View.new(element: '#my-view', template: 'my_view') }
end
Views
Views have two main attributes, configurable either via DSL or inside the initializer.
class MyView < Clearwater::View
element "#my-view"
template "my_view"
end
This will rely on there being a container element with the CSS selector #my-view if it needs to be rerendered on its own. If the parent is being rendered as well (such as on initial render or navigation from another route), this isn't necessary.
The template, however, is required. This is the path/filename of the template being rendered. This particular view will render the template in app/assets/javascripts/templates/my_view.slim if you're using the opal-slim gem (or the equivalent Haml template if using opal-haml).
The view serves as the context of the template, so methods defined in the view are available inside the template. This allows for things like form helpers (available by subclassing Clearwater::FormView instead of Clearwater::View).
The view also delegates to the controller, so you can access app state without explicitly requesting it from the controller.
Templates
Templates can be written in your favorite Ruby template language. I prefer Slim so I wrote the opal-slim wrapper to compile Slim templates for Opal. Adam Beynon, the creator of Opal, wrote the opal-haml gem to accomplish the same for Haml (also, thanks to Adam for the inspiration for the opal-slim gem!).
I believe ERb support is built-in, but I haven’t tested that because I don’t use it. :-)
Outlets
Similar to Ember routes, controllers can be nested. Your controllers have an outlet attribute that points to the next subordinate controller. The router wires this up as part of the routing process based on the URL so you should never need to adjust it manually.
Views have an outlet method you can use in your templates. This is used for rendering the subordinate view.
If there is no subordinate route, but you still want to render content where the outlet would go, you can set up a default outlet for the controller:
class MyController < Clearwater::Controller
default_outlet { MyDefaultOutletController.new }
end
This is useful if, for example, you are rendering a blog but a specific article hasn’t been chosen yet. This default outlet could render the most recent article or the most recent 5-10 or whatever makes sense for your application.
Will it blend?
The most common problems with front-end frameworks are how they break the back button, click events with modifier keys (Command/Ctrl-clicking to open a new tab, for example), and linkability.
Back/forward-button usage is detected by the onpopstate event. The app monitors this event and rerenders based on the updated URL.
Clicking links using any modifier keys are completely ignored by Clearwater, so we can honor the browser's default behavior and not piss off users.
Linkability, the ability to bookmark/share links to specific routes (and, by extension, refresh the page and have it render in the same state), is provided by similar functionality to the back/forward-button handling mentioned above. That is, the app rendering is based entirely on the URL, so once the app loads, it will render the same page it showed before.
"Just use JavaScript, you lazy bum!"
A lot of JS proponents say we should just use JavaScript. That's an easy position to take when it's a language you like, but I don't particularly enjoy JavaScript. When Rails was first announced, developers from the .NET and Java communities said the same things, that we should just use their stack, but Rubyists wanted something better and, as a community, have made Rails one of the most popular web frameworks in the industry.
My point is that we don't have to settle for JavaScript. I’m not trying to say Clearwater is the solution to all your front-end woes. It’s not the next Ruby on Rails (well, it’s possible, but I’m not claiming that right now). However, there are several Opal frameworks on the rise: Volt, Vienna, RubyFire.
"But debugging!"
Another argument people make against using languages that compile to JavaScript is that you still need to understand JavaScript, and that’s absolutely true, but it’s not a convincing argument against Opal.
You also need to understand Java to debug Scala or Clojure apps on the JVM. You need to understand HTTP to build nontrivial Rails apps. You need to understand SQL to do just about anything with ActiveRecord. A lot of abstractions in common usage today have leaks. I don't like that any more than anyone else (to be honest, I complain about it pretty regularly), but it's part of what we do. You always need to understand underlying mechanisms of your app and architecture.
Opal also supplies source maps to the browser to aid debugging purposes in development to show you the Ruby file and line of code (instead of the compiled JS) in stack traces. It's not always perfect, but it's getting better.
So is it usable?
I'm sure there are kinks to work out, but it's usable in its current form. The project readme has an example of a minimal Clearwater application using a simple controller and a Slim template.
Over time, I'll be setting up docs and putting together a few screencasts to show off some more of Clearwater's functionality. In the meantime, if you'd like to chat about it, you can tweet at me or say hi in the Clearwater Gitter channel (I'm @jgaskins in the channel).
Hashie vs OpenStruct vs POROs
At work the other day, we were discussing the merits of Hashie::Mash vs OpenStruct (then yesterday I saw this article from Richard Schneeman which also discusses them). One of the things we discussed was the performance aspect of one over the other. We didn't have any actual benchmarks to use, so I went ahead and wrote some out.
Hashie alloc 233.387k (± 3.3%) i/s - 1.184M
OpenStruct alloc 78.249k (± 4.3%) i/s - 395.395k
Hashie access 549.476k (± 2.1%) i/s - 2.772M
OStruct access 2.863M (± 4.3%) i/s - 14.390M
This shows that initializing a Hashie::Mash is 2.7x as fast as an OpenStruct, but in accessing attributes (each one had 3 attributes and I hit them all), OpenStruct led by a factor of 5.2.
When you consider that initialization happens once and attribute access happens frequently (you will always access attributes at least as often as initializing, otherwise the object isn't worth a whole heck of a lot), you'd want the one with faster accessors, so you'd want to use OpenStruct, right?
Nope.
The Method Cache and You
All of the major Ruby implementations have a data structure that stores the locations of methods in memory. Looking these methods up every time you access them is slow, so they make use of a cache that speeds up lookup of methods you're actually using. This explanation is intended to be a bit hand-wavy because there are other articles that talk about the method cache. Just know that it's important to the performance of your app.
Several things you can do in Ruby will invalidate some or all of that method cache depending on which Ruby implementation you're using. define_singleton_method, extend, or defining a new class will all do it. When this happens, the VM has to fall back on slow method lookup.
Why do I tell you all this? Because this happens every time you initialize an OpenStruct. This is the reason it's slow to instantiate.
The only way to provide those dynamic accessors without using define_singleton_method is to use method_missing. That is what Hashie::Mash uses. Unfortunately, that comes with its own drawbacks.
Excuse me, have you seen my method?
method_missing is a powerful tool in Ruby, just like dynamic method definition. It helps us do a lot of amazing metaprogramming things. However, that flexibility comes with performance tradeoffs. It's important to realize what all happens before that method is invoked.
- Send an object a message
- VM doesn't have a method cached for that message, so we invoke the slow-lookup route I mentioned in the previous section
- VM checks the object's singleton class (every object has one that contains the methods defined using
define_singleton_method; you can check it out usingobject.singleton_class) - VM walks up the ancestor chain of the object's class (
object.class.ancestors) to find a method that handles that message.
- VM checks the object's singleton class (every object has one that contains the methods defined using
- Invoke
method_missing
When you send an object a message and the VM doesn't have that method cached (it doesn't exist), so it has to hit the slow-lookup route I mentioned in the previous section. This checks the object's singleton class first (every object has one that contains the methods defined using define_singleton_method; you can check it out using object.singleton_class), then walks up the ancestor chain of the object's class (object.class.ancestors) to find a method that handles that message.
For Hashie::Mash in a Rails app, there are no fewer than 17 classes and modules it has to check. In the benchmark above, there were 9. This means Hashie::Mash will perform significantly worse after Rails injects all those mixins into your ancestor chain. Our app had roughly a 12% decrease in Hashie::Mash access performance.
So … what do you want me to do?
If you want to be able to access attributes with a dot instead of brackets, it really is best to write a class for it. It's faster to allocate and faster to get attributes. Here's the same benchmark as above including plain-old Ruby objects (POROs).
Hashie alloc 233.387k (± 3.3%) i/s - 1.184M
OpenStruct alloc 78.249k (± 4.3%) i/s - 395.395k
PORO alloc 558.183k (± 2.7%) i/s - 2.812M
Hashie access 549.476k (± 2.1%) i/s - 2.772M
OStruct access 2.863M (± 4.3%) i/s - 14.390M
PORO access 8.096M (± 4.9%) i/s - 40.490M
Allocating a PORO is faster than accessing 3 attributes on a Hashie::Mash. In fact, you could allocate a PORO and access all of its attributes with time to spare before a pre-allocated Hashie::Mash just touches its attributes.
Don't get me wrong, using Hashie::Mash or OpenStruct is awesome for prototyping and just getting a feature out the door, but performance is important, so I'd always recommend writing a class for the object you're trying to pass or return. This also has a happy side effect of documenting what that data is; an object telling me explicitly that it's an Article is better than me having to figure it out based on keys and values of a hash.


